OmniVLA: An omni-modal vision-language-action model for robot navigation

Hirose, Noriaki, et al. “OmniVLA: An omni-modal vision-language-action model for robot navigation.” arXiv preprint arXiv:2509.19480 (2025). arXiv (2025. 09), citation 7 (26.03.12 기준)
UC Berkeley 동일 연구팀 관련 연구 (Navigation)
Shah, Dhruv, et al. “ViNT: A Foundation Model for Visual Navigation.” Conference on Robot Learning. PMLR, 2023. CoRL 2023, citation 290 (26.03.12 기준)
Sridhar, Ajay, et al. “Nomad: Goal masked diffusion policies for navigation and exploration.” 2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024. ICRA 2024, citation 293 (26.03.12 기준)
…
- 들어가기 앞서 Omni-modal과 Multi-modal의 차이
데이터 처리의 통합성 과 지연 시간(Latency)
Multi-modal (Late Fusion 방식): 오디오를 들으면 먼저 텍스트로 변환(STT)하고, 그 텍스트를 언어 모델이 해석한 뒤, 다시 음성으로 변환(TTS). 이 과정에서 정보의 손실(말투, 감정, 배경 소음 등)이 발생하고 응답 속도가 느림
Omni-modal(Any-to-Any 방식): 중간 변환 과정 없이 오디오 신호를 그대로 입력받아 즉시 처리. 단일 신경망이 텍스트, 이미지, 소리를 동시에 학습하므로 사용자의 목소리 톤이나 영상의 미세한 표정 변화까지 실시간으로 파악하여 반응
핵심 기술: 통합 토큰화 (Unified Tokenization) omni-modal의 근간은 모든 데이터를 ’토큰(Token)’이라는 공통 분모로 만드는 기술에 있다. 텍스트를 숫자로 바꾸듯, 이미지의 조각이나 소리의 파형도 동일한 규격의 토큰으로 변환하여 하나의 트랜스포머(Transformer) 모델에 넣는 방식. 이를 통해 모델은 “사과”라는 글자와 사과의 이미지, 사과를 씹는 소리를 동일한 개념으로 연결해 이해하게 된다.
인간의 인지 구조와 유사해짐.
정보의 비손실성: 텍스트로 요약되지 않는 비언어적 맥락(뉘앙스, 시각적 구도 등)을 AI가 직접 파악
실시간 상호작용: 변환 단계가 생략되면서 인간과 거의 동일한 속도로 대화가 가능
추론 능력의 확장: 시각적 정보와 청각적 정보를 결합해 복합적인 문제를 해결
high-capacity VLA 백본(OpenVLA)을 활용하며 무작위 모달리티 융합(Randomized modality fusion) 전략을 통해 2D pose, 1인칭(Egocentric) 이미지, 자연어라는 세 가지 주요 목표 모달리티와 이들의 조합을 학습. 사용할 수 있는 데이터셋의 범위를 넓힐 뿐만 아니라, 정책(Policy)이 더 풍부한 기하학적, 의미론적, 시각적 표현을 개발하도록 유도.
목표 지점이 가까울 때는 “건물을 따라 이동해서 입구로 가라”와 같이 언어로 설명하는 것이 편리한 반면, 멀리 떨어진 목표는 GPS 좌표로 설명하는 것이 더 효과적일 수 있다. 진정한 범용 내비게이션 정책은 성공적인 수행을 위해 여러 정보원을 활용해야 하는 과업을 수행할 수 있어야 한다.
본 연구는 여러 모달리티로 표현된 목표 사양을 사용하여 내비게이션 할 수 있는 일반화 가능한 정책을 훈련하는 것을 목표로 한다.
파운데이션 모델을 훈련하려면 가능한 한 많은 데이터를 활용해야하는데, 대부분 1인칭 이미지, 2D 포즈 또는 자연어와 같은 단일 종류의 작업 표현으로만 훈련된다. 이는 사용 가능한 데이터셋을 원하는 작업 표현과 일치하는 것(예: 언어 레이블이 있는 데이터셋만)으로 제한하고, 테스트 시 모델 사용 방식을 제약하며, 모델이 작업과 관측을 처리하는 방식을 잠재적으로 제한한다.
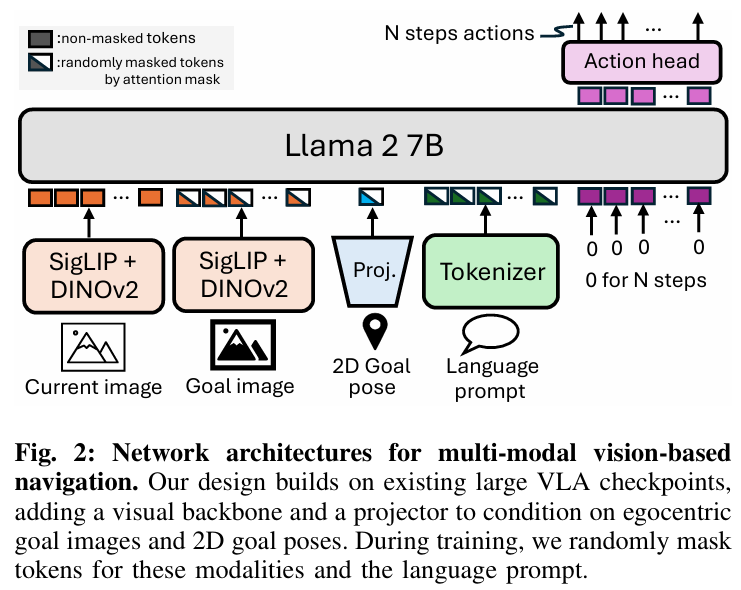
0 for N steps에 들어가는 0은 자리 표시자(Placeholder)! 미래 N단계 액션을 계산할 수 있도록 미리 공간을 만들어 주는 토큰
본 연구에선 (1) 2D 포즈, (2) 1인칭 이미지, (3) 자연어라는 세 가지 기본 모달리티를 통해 지정된 목표로 모델을 훈련. 이러한 서로 다른 모달리티를 동시에 해석하도록 학습함으로써, 모델은 과업의 기하학적, 시각적, 의미론적 정보에 대해 더 풍부한 이해를 발달시켜야 하며, 그 결과 더 강력한 내비게이션 모델이 탄생
다양한 작업 모달리티를 통합하는 최초의 엔드투엔드 내비게이션용 VLA 모델.
- OpenVLA 아키텍쳐
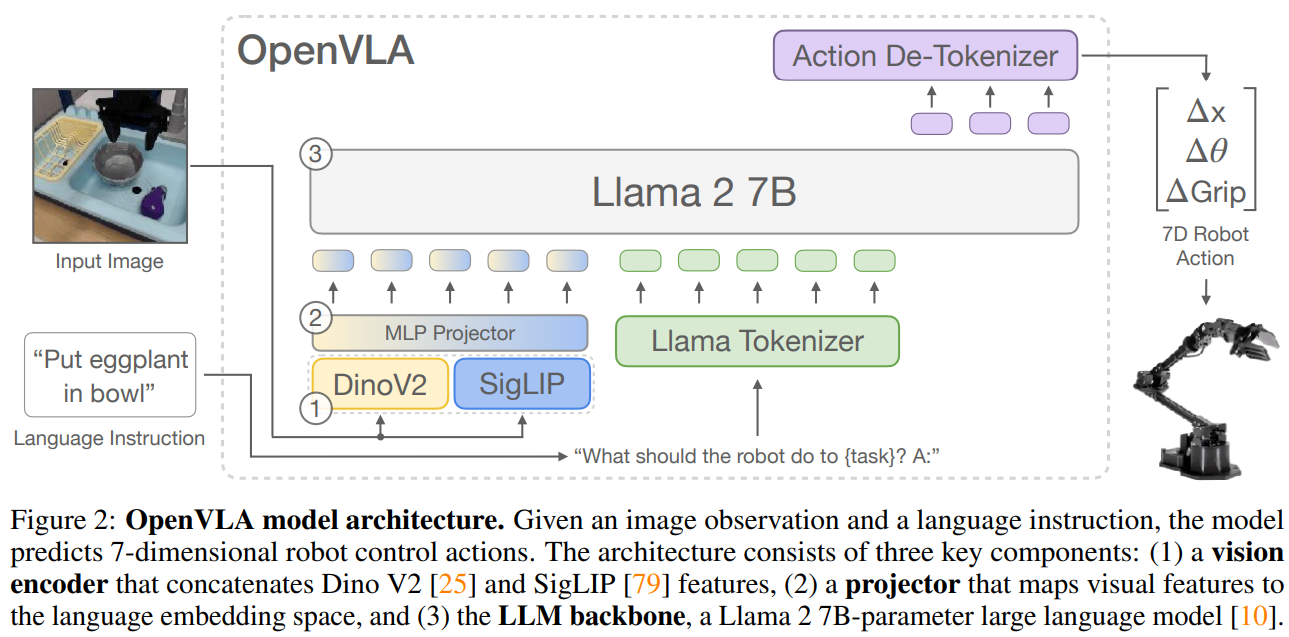
OpenVLA: 행동을 ‘단어 토큰’ 으로 취급. 예를 들어 로봇이 움직이는 것을 “Move Forward”라는 단어를 생성하듯 처리. (자기회귀 방식) 행동 출력: 이산 토큰 (Discrete Tokens). 한 번에 하나씩 예측 (x, y, z, roll, pitch, yaw, gripper …)
OmniVLA: OpenVLA의 마지막 단계를 뜯어내고 ‘Action Head’ 를 새로 부착. 이 헤드는 단어를 뱉는 게 아니라, 로봇의 속도와 방향 값을 ’연속적인 숫자(Regression)’로 한꺼번에 계산하여 출력. 행동 출력: 연속 액션 (Continuous Actions). 미래 N단계를 한꺼번에 예측 (선속도1, 각속도1, 선속도2, 각속도2 … 선속도N, 각속도 N) → 이 값들은 로봇 전체의 움직임을 통합 제어하는 하이 레벨(High-level) 커맨드. 바퀴 혹은 발마다 다른 값을 내보내는 것이 아닌, 로봇 본체가 “초속 얼마로 전진하고 초당 몇 라디안으로 회전하라”는 통합 속도 명령을 내림. 이후 내부 컨트롤러에서 바퀴의 경우 받은 속도 명령을 바퀴 회전수로 변환하고, 사족보행 로봇은 네 다리의 관절 각도로 변환하여 걷게 만든다.
OpenVLA는 기본적으로 ’이미지+언어’만 이해. 하지만 OmniVLA는 ’내비게이션 전용 감각’을 추가.
OmniVLA의 추가 입력 블록:
2D Goal Pose: 목표 지점의 좌표 \((x, y)\) 를 직접 입력받는 ’Projector’가 추가
Goal Image: 도착지 사진을 보고 길을 찾는 기능 추가
? 2D Pose(\(p_g\)): 실외 환경에서 GPS 데이터를 기반으로 생성. (로봇 기준의 상대적 위치)
로봇의 현재 위치와 목표 지점의 위치를 GPS로 추정
이 두 지점의 차이를 계산하여 로봇을 기준으로 한 상대적인 목표 좌표 \(p_g\) 를 도출
주로 25~100m 사이의 장거리 내비게이션 과업에서 “어디로(Where)” 가야 할지를 알려주는 핵심 신호
OmniVLA는 거의 10,000시간에 달하는 실제 내비게이션 데이터로 훈련되었으며, 이는 엔드투엔드 내비게이션 정책을 위한 가장 큰 사전 훈련 데이터셋
Manipulation(Related Paper)에서 검증된 ‘입력 마스킹’ 전략을 내비게이션으로 이식
OmniVLA
OmniVLA Architecture - 기반 구조: 7B-parameter의 OpenVLA 모델을 기반으로 하며, 로봇의 현재 시각적 관측은 시각 인코더를 통해 처리
목표 조건화 지원: 시각(Visual), 위치(Positional), 언어(Language)라는 세 가지 서로 다른 모달리티를 지원하며, 이들은 동시에 지정될 수도 있다. LLM 백본의 입력 역할을 하는 공유 토큰 공간(Shared Token Space)으로 투영
모달리티 드롭아웃: 훈련 및 추론 중에 목표 모달리티를 유연하게 마스킹하기 위해 ‘모달리티 드롭아웃’ 기법을 사용
학습 시 배치(Batch)의 각 샘플에 대해 사용 가능한 목표 모달리티(2D Pose, 1인칭 이미지, 언어 프롬프트) 중 일부를 독립적으로 무작위 선택
어텐션 마스크(Attention Mask): 선택되지 않았거나 사용할 수 없는 모달리티는 무작위 값으로 채워지며 어텐션 마스크를 통해 모델이 오직 선택된 모달리티에만 집중하도록 강제
액션 생성: OpenVLA-OFT[30]을 따라 LLM 출력에 선형 액션 헤드를 추가하여 일련의 액션 \(\{\hat{a}_i\}_{i=1...N}\)을 생성
Edge 버전: 리소스가 제한된 배포 환경을 위해 50M-parameter의 내비게이션 트랜스포머(ViNT[8])기반의 소형 OmniVLA-edge 아키텍처도 구현
Training OmniVLA 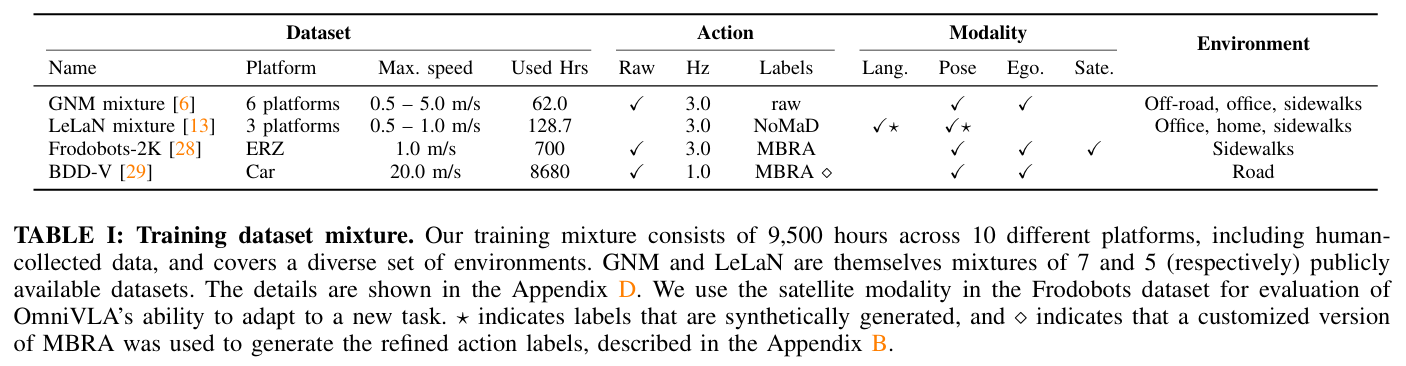
훈련 데이터: 13개의 공개 데이터셋을 결합하여 10가지 플랫폼에서 수집된 총 9,500시간의 데이터를 사용. 수동으로 수집된 라벨뿐만 아니라 노이즈가 있을 수 있는 합성 라벨 및 재주석(re-annotation) 과정을 거친 액션이 포함
합성 액션 및 재주석: Frodobots 데이터셋에는 MBRA[11]을, LeLaN 데이터셋에는 NoMaD[9]를 사용하여 생성된 합성 액션을 훈련에 활용. 특히 자율주행 차 데이터인 BDD-V의 경우, 일반 로봇과의 체급 차이(속도 등)를 해결하기 위해 별도의 재주석 모델을 훈련하여 적절한 합성 액션을 생성
훈련 방법: 무작위 드롭아웃 방식을 사용하여 가용한 모든 모달리티에 대해 훈련, 이는 모델의 효율성과 일반화 성능을 높인다. 각 샘플에 대해 사용 가능한 목표 모달리티 중 독립적으로 샘플링하여 조건부 입력 \(t_m\) 을 형성. 훈련 단계마다 사용되지 않거나 가용하지 않은 모달리티를 제외하는 어텐션 마스크(attention mask)를 구성
목적 함수(Objective): 정책은 \(\{\hat{a}_{i}\}_{i=1...N} = \pi_{\theta}(I_{c},I_{g},p_{g},l_{g},t_{m})\) 로 정의.
\((I_{c},I_{g},p_{g},l_{g},t_{m})\) = (egocentric current image, egocentric goal image, 2D goal pose, language prompt, randomly selected modality)
다음 손실함수 \(J_{il}\) 를 최소화하도록 모델을 업데이트 \[ J_{il}=\frac{1}{N}\sum^N_{i=1}(a_i^{ref}-\hat{a}_i)^2 \]
훈련 세부 사항:
액션 청크 사이즈 N은 8로 설정됨 (3Hz 기준 2.4초 해당).
데이터 샘플링 비율은 모달리티 균형을 위해
LeLaN: GNM: Frodobots: BDD-V = 4:1:1:1로 설정.
8대의 H100 GPU에서 LoRA를 적용하여 학습 파라미터를 약 5%로 제한함으로써 배치 사이즈(효과적 배치사이즈 224)와 훈련 안정성을 최적화
Experimental Setup
A. Navigation tasks
3가지 내비게이션 작업을 고려.
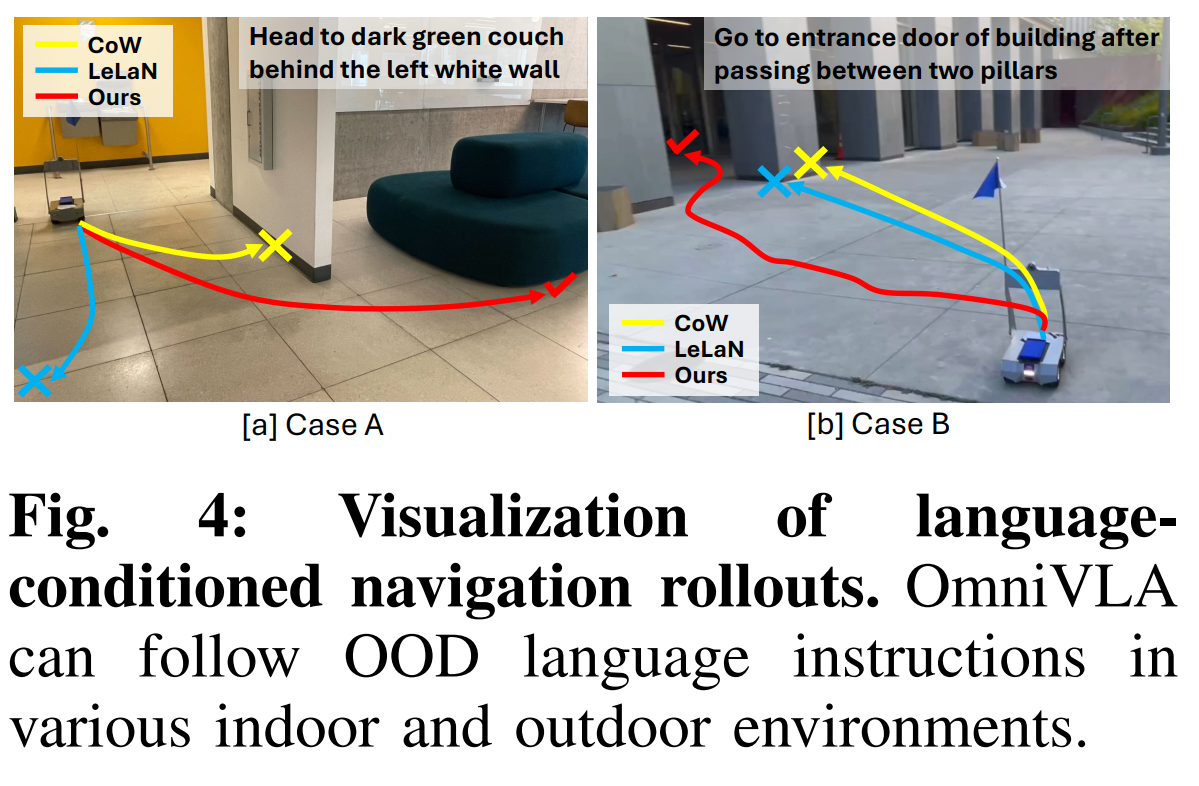
Language-conditioned navigation 언어 조건부 내비게이션 OmniVLA가 로봇을 목표 위치로 안내할 뿐만 아니라, 그 과정에서 어떻게 행동해야 하는지 지정하는 언어 프롬프트를 얼마나 잘 수행하는지 평가.
사무실, 주방, 현관, 홀, 공원, 보도 등 40개 환경에서 다양한 언어 프롬프트를 사용하여 평가를 진행
목표 지점은 로봇의 초기 위치에서 5~30미터 거리에 배치
Large pretrained model의 이점을 평가하기 위해 훈련 데이터에 존재하지 않는 OOD 언어 프롬프트를 도입. 훈련 데이터는 주로 ’X로 이동하라’와 같은 객체 도달 지침 위주였으나, 연구에선 실험의 절반에서 목표까지 내비게이션하는 구체적인 방식을 지정하는 OOD 프롬프트를 설계
로봇의 시작 지점과 목표 사이에 장애물이 배치된 17개의 환경을 선택하여 정책의 핵심 내비게이션 능력을 더욱 까다롭게 테스트
Egocentric goal image-conditioned navigation 1인칭 목표 이미지 조건부 내비게이션
1인칭 목표 이미지가 주어지면, 최대 3미터 거리에 있는 목표 지점까지 로봇을 이동시키는 과업을 수행
이 범위를 확장하기 위해 기존 시각 기반 접근 방식을 따라 8개의 환경에서 위상 메모리(topological memory) 를 사용하여 더 먼 거리의 목표까지 내비게이션 할 수 있도록 함
?위상 메모리? 어떤식으로 이용 및 작동?목표 그래프를 구축하기 위해 1Hz로 이미지 관측치를 기록
전개 시에는 첫 번째 관측치에서 시작하여 매 단계마다 현재 위치와 가장 가까운 노드를 추정하고, 다음 노드의 이미지를 정책에 목표 이미지(\(I_g\))로 제공
Goal pose-conditioned navigation 2D Goal poses가 주어지면, 정책은 로봇의 초기 위치에서 25~100 미터 떨어진 목표까지 내비게이션.
GPS를 사용하여 로봇과 목표의 위치를 추정.
매 단계마다 목표 포즈에 대한 로봇의 상대적 포즈(\(p_g\))를 계산.
평가를 위해 7개의 환경을 선택했으며, GPS 오차(jitter)를 고려하여 각 환경에서 서로 다른 시간에 3번의 테스트를 수행
B. Mobile Robot Platforms
저가형 모바일 로봇인 FrodoBots ERZ 플랫폼에서 OmniVLA를 평가 이 로봇은 전후방 카메라, GPS, IMU(자이로스코프, 가속도계, 나침반), 4개 바퀴의 속도 센서 등 여러 센서를 갖추고 있다. 훈련된 내비게이션 정책은 로봇에 선형 및 각속도 명령을 전송하여 인터페이스. 또한, 플랫폼 간 일반화 성능을 평가하기 위해 바퀴형 로봇인 VizBot과 사족보행 로봇인 Unitree Go1이라는 두 가지 추가 플랫폼에서도 정책을 평가.
? 플랫폼은 로봇의 종류라고 이해하면 될 것 같음! 여기서 사용된 FrodoBots ERZ는 센서 데이터(이미지, GPS, IMU 등)를 웹 API를 통해 인터넷으로 로컬 PC(서버)에 전송하는 방식. 이에 OmniVLA, OmniVLA-edge 모두 로봇 내부의 PC만으로 동작이 아니라 서버를 이용한 것으로 확인. (서버 통신 상황 구축을 위해 일부러 골랐을 수도 있음.)
C. Baselines OmniVLA를 모든 모달리티에 걸쳐 7개의 베이스라인과 비교. from scratch로 훈련된 model-free 정책(ViNT, NoMaD, MBRA), 인터넷 규모의 비디오를 활용할 수 있는 방법(LeLaN), CLIP과 같은 기성 시각 표현을 사용하는 방법(CoW), 그리고 최신 VLA 모델(Counterfactual VLA)이 포함
NoMaD: 2D goal pose-conditioned navigation을 위해 탐색 모드에서 30개의 후보 궤적을 생성하고, 최종 예측 위치가 목표 포즈(\(p_g\))에 가장 가까운 궤적을 선택하여 로봇을 제어
CoW: language-conditioned navigation을 위해 현재 관측치와 목표 객체를 설명하는 프롬프트를 OWL-ViT B/32 detector에 제공하여 객체의 바운딩 박스를 추정. 깊이 정보를 추정하고 포인트 클라우드를 재구성하여 목표 객체의 포즈를 추정하며, 상태 격자 모션 플래너를 사용하여 속도 명령을 생성
Other VLA backbones: VLA 아키텍처와 사전 훈련의 역할을 더 깊이 이해하기 위해, 1B 규모의 MiniVLA와 500M 파라미터 규모의 SmolVLA에도 이 Omni-modal goal-conditioning 전략을 구현
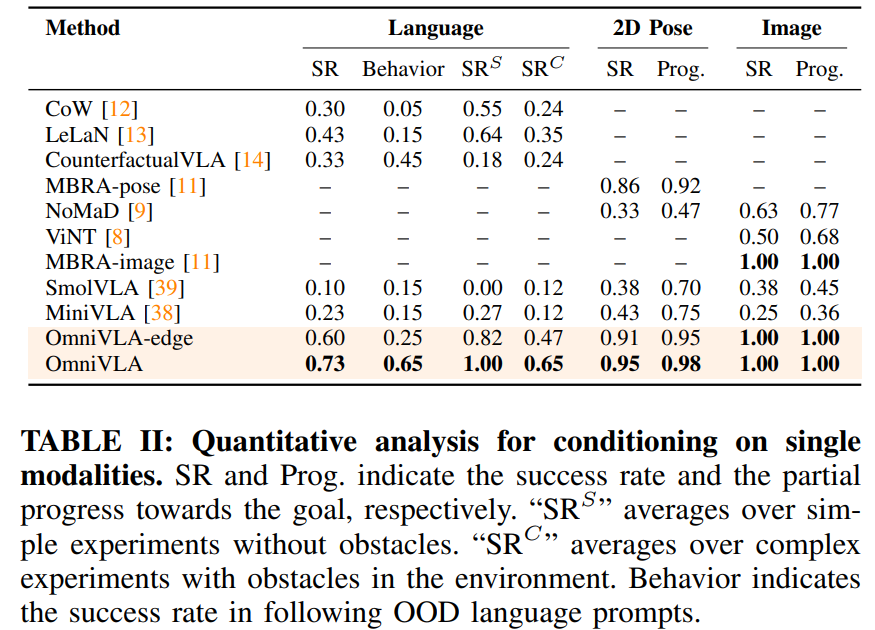
Evaluating Omni-modal Navigation
Q1. 옴니모달 사전 훈련이 단일 모달리티 내비게이션 정책보다 우수한 성능을 보이는가? A. Yes. 개별 모달리티에 사용 가능한 데이터셋보다 실질적으로 더 큰, 대규모의 매우 다양한 훈련 혼합 데이터로부터 일반화된 내비게이션 능력을 학습한 결과. 또한 사전 훈련된 VLA 아키텍처와 데이터의 선택이 성능에 큰 영향을 미친다는 것을 확인
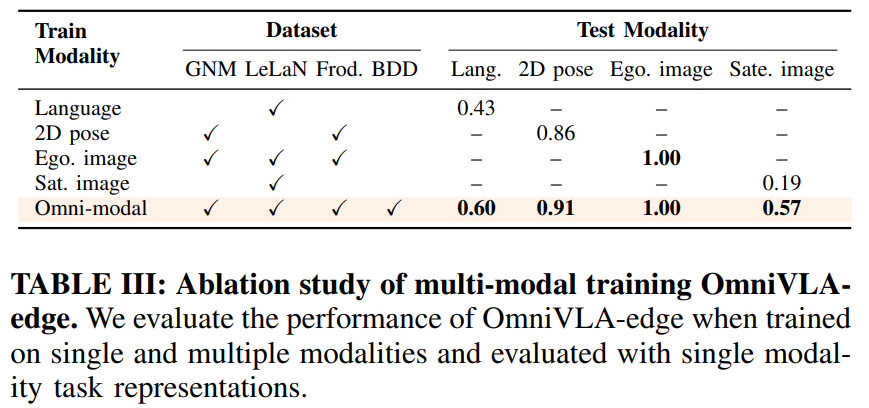
Dataset Ablation: 여러 모달리티를 공동으로 학습함으로써 OmniVLA는 모든 데이터셋에서 핵심 내비게이션 행동을 배우고, 제한된 데이터로 학습된 단일 모달리티 정책에 비해 보지 못한 환경에 대해 더 강력한 일반화 성능을 달성. 또한 매우 다양한 cross-embodiment data인 BDD-V 데이터셋을 포함한 결과, BDD-V 없이 학습된 정책이 실패한 사례의 약 절반 정도를 성공으로 전환하는 것을 관찰하였다.
모델 아키텍처를 고정한 채 더 크고 다양한 데이터 혼합으로 학습했을 때의 이점을 확인
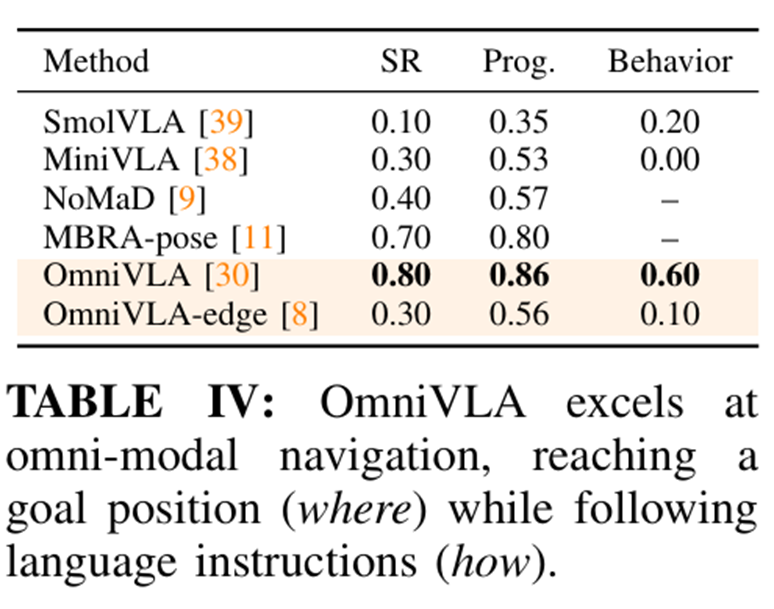
Q2. OmniVLA가 여러 목표 모달리티의 조합(Composition)을 따를 수 있는가? 10개의 서로 다른 환경에서 2D goal pose(‘어디로’)와 행동 언어 지시(‘어떻게’)를 모두 제공하는 실험 수행, 제공된 프롬프트는 훈련 데이터셋에 포함되지 않은 OOD 형태.
OmniVLA는 프롬프트와 goal pose 모두에 주목하는 능력을 보여주며 80%의 성공률을 기록했고 언어 수행 능력 저하는 단 5%에 불과
OmniVLA-edge는 제한된 모달리티 용량으로 인해 언어 지시 처리에 실패
Q3. OmniVLA를 새로운 목표 모달리티, 환경 및 로봇 플랫폼(Embodiments)에 적응시킬 수 있는가? 파운데이션 모델로서의 역량을 평가하기 위해 (i) 새로운 목표 모달리티 학습, (ii) 새로운 데이터셋 미세 조정, (iii) 새로운 로봇 플랫폼 제어라는 세 가지 측면을 평가
위성 이미지 모달리티 학습: 위성 이미지 전용 모델(0.19)에 비해 OmniVLA-edge를 적응시킨 결과 성능이 크게 향상(0.62). 이는 OmniVLA가 학습한 교차 모달 표현이 사전 학습 중에 습득한 유용한 내비게이션 능력을 유지하면서도 새로운 작업 학습을 촉진할 수 있음을 보여준다.
환경 및 데이터 적응: 보지 못한 테스트 환경에서 수집된 단 1.2시간의 데이터만으로 미세 조정한 결과, 두 모달리티 모두에서 성능이 향상
로봇 플랫폼 일반화: 여러 로봇의 데이터로 훈련된 모델의 범용성을 보여주기 위해 바퀴형 로봇인 VizBot과 사족보행 로봇인 Go1에 배포. 가장 까다로운 언어 조건부 내비게이션 작업을 테스트한 결과, 두 로봇 모두 추가 조정 없이도 자연어 지시를 따르고 목표 지점에 도달할 수 있었다.

- OmniVLA-edge는 내비게이션 작업에 특화된 아키텍처를 채택하여 크기 대비 탁월한 성능을 달성. 다만 언어 추종 능력에서는 OmniVLA-edge와 OmniVLA 사이에 상당한 격차가 존재, 이는 사전 훈련된 VLM에서 상속된 시각-언어 사전 지식의 이점을 강조
Appendix
A. OmniVLA-edge based on vision-based navigation policies
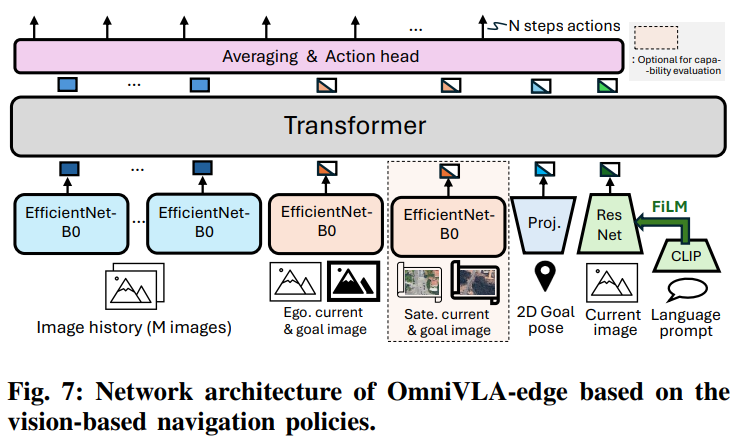
VLA 기반 아키텍처 외에도 ViNT[8], NoMaD[9], MBRA[11], LeLaN[13]과 같은 기존의 단일 모달리티 시각 기반 내비게이션 정책을 바탕으로 또 다른 네트워크인 OmniVLA-edge를 설계
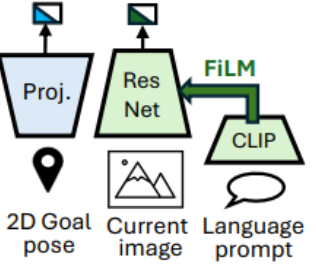
구조적 확장: 1인칭 목표 이미지 조건부 내비게이션을 위한 ViNT를 기반으로 하여, 2D 목표 포즈 조건화를 위한 프로젝터(projector)와 언어 프롬프트 조건화를 위한 FiLM(Feature-wise Linear Modulation) 기반의 ResNet 및 CLIP 네트워크를 추가[13, 26]
어텐션 마스크: VLA 기반 모델과 유사하게, 데이터 샘플링 과정에서 선택된 모달리티 \(t_m\) 에 따라 어텐션 마스크를 설계
조기 융합 (Early Fusion): VLA 기반 네트워크와 달리, 이 모델은 트랜스포머에 입력하기 전에 각 모달리티의 토큰을 조건화하는 조기 융합 방식을 채택
왜 사용?7.5B 모델이 방대한 파라미터로 나중에 정보를 합쳐도(Late Fusion) 충분한 추론이 가능하다면, 50M 모델인 Edge 버전은 처음부터 정보를 꽉 묶어서(Early Fusion) 트랜스포머가 처리해야 할 부담을 줄여준 것. 이는 저사양 하드웨어에서 효율을 극대화하기 위한 선택시간적 일관성: 경량화된 아키텍처 내에서 시간적 일관성을 유지하기 위해, 마지막 \(M=5\) 개의 이미지 단계로부터 추출된 토큰을 입력으로 제공
M=5의 의미?단순히 현재 사진만 보는 게 아니라 과거 5장까지 함께 본다는 것은, 로봇이 자신의 움직임 흐름을 이해하게 하여 급격한 방향 전환이나 떨림을 방지하려는 의도액션 생성: NoMaD[9]의 방식을 따라 트랜스포머가 생성한 토큰들의 평균을 계산한 뒤, 이를 액션 헤드에 전달하여 일련의 액션 \(\{\hat{a}_{i}\}_{i=1...N}\) 을 생성. 그림 7에 나타난 바와 같이 EfficientNet-B0, ResNet, CLIP 요소들에는 사전 훈련된 가중치가 사용
검증된 부품의 재조립새로운 걸 만든 게 아니라 이미 검증된 ’사전 학습된 부품’들을 내비게이션이라는 용도에 맞게 재배치. 임베디드 환경에서 이 모델을 돌리려 한다면 이 부록 A의 구조가 가장 핵심적인 참고 자료가 될 것
? Ego. current & goal image가 EfficientNet-B0에 어떤식으로 같이 들어가는지?
별도의 토큰으로 들어가는 것이 아닌 신경망에 들어가기 직전 채널(Channel) 방향으로 합쳐짐(Concatenate). 일반적인 이미지가 RGB 3채널이라면, 현재 이미지(3채널)와 목표 이미지(3채널)를 포개어 총 6채널짜리 데이터를 만든다.
묶은 이유는 ‘현재 내 모습’과 ’내가 도달해야 할 목표’ 사이의 시각적 차이를 한 번에 계산하게 만들기 위함
? ResNet + CLIP + FiLM 부분은? - 말(언어)로 설명된 목표를 현재 시야에서 찾아내는 과정을 담당. 단순히 텍스트를 따로 읽는 것이 아니라, 텍스트가 시각 처리에 직접 개입하는 FiLM(Feature-wise Linear Modulation) 기법을 사용
- CLIP: 사용자의 언어 프롬프트(예: "오른쪽 선반으로 가")를 읽고 그 의미를 담은 고차원 벡터로 변환
- ResNet: 현재 로봇의 시야(Current image)를 훑으며 공간적인 특징들을 추출
- FiLM: CLIP이 만든 언어 벡터는 FiLM 레이어를 통해 '필터' 역할을 하는 파라미터(Scale, Shift)로 변환. 이 필터가
ResNet의 중간 특징 맵(Feature map)에 곱해지고 더해진다. 결과적으로 언어 지시가 만약 "빨간 사과"라면, FiLM은 ResNet이 보고 있는 이미지에서 '빨간색'과 '둥근 형태'에 해당하는 신경망의 반응을 증폭시키고 나머지는 억제한다.- OmniVLA(거대 모델)와의 결정적 차이 Edge가 왜 가벼운 지 알 수 있다.
OmniVLA (Fig. 2): 각 모달리티를 아주 비싼 인코더(SigLIP, DINOv2)로 각각 뽑아서 트랜스포머에 길게 늘어놓는다. 트랜스포머가 스스로 알아서 관계를 찾으라는 ‘방임형 학습’
OmniVLA-edge (Fig. 7): 트랜스포머가 고민할 시간을 줄여주기 위해, 채널을 합치거나(Current & Goal) FiLM으로 정보를 섞어(Language + Current) ’전처리된 힌트’를 토큰으로 던져준다. 50M라는 작은 크기로도 옴니모달 수행이 가능한 비결
? ViNT에서 구조가 어떻게 달라졌는지?
ViNT (단일 모달): 기본적으로 1인칭 이미지(Egocentric) 만을 목표로 입력받음. 시각적 관측 데이터를 처리하기 위해 EfficientNet-B0 인코더를 사용
OmniVLA-edge (다중 모달): 이미지뿐만 아니라 언어 명령(Language), 2D 좌표(Pose), 위성 이미지(Satellite)를 동시에 처리할 수 있도록 설계. 이를 위에 EfficientNet 외에 아래 요소 추가
언어 처리: 자연어 지침을 이해하기 위해 CLIP 및 ResNet 네트워크와 FiLM(Feature-wise Linear Modulation) 레이어를 결합하여 구조 확장
좌표 처리: GPS 등 2D 위치 정보를 토큰화하기 위한 별도의 프로젝터(Projector) 추가
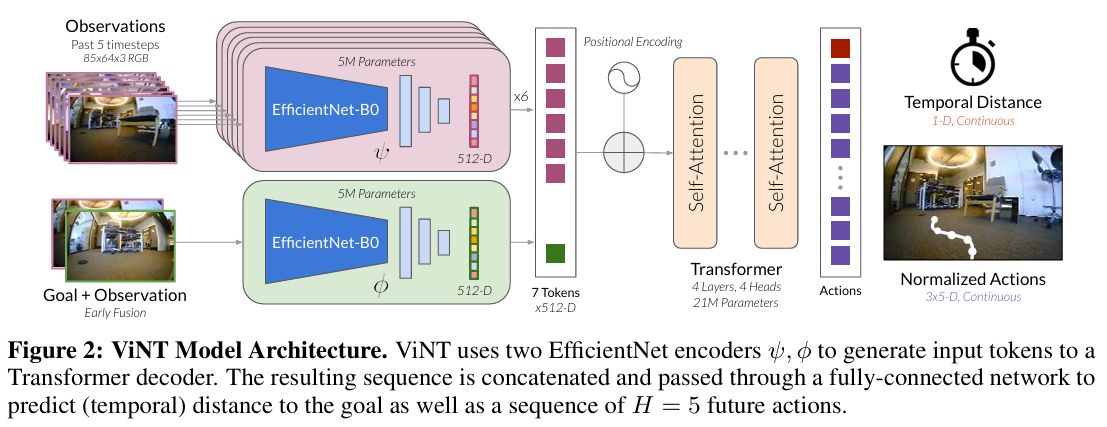
ViNT 모델 아키텍처. 여기서 2D Goal pose를 위한 프로젝터, 언어 지시를 위한 ResNet과 CLIP이 추가된 것으로 보임.
B. Reannotation model for BDD-V dataset
MBRA(Model-Based Reannotation). 데이터 재해석 모델. (데이터 변환기 역할 수행!)
로봇이 직접 수집하지 않은 ’날것’의 데이터(예: 자동차 주행 영상이나 GPS 로그)를 가져와서, 우리 로봇이 실제로 따라 할 수 있는 실행 가능한 행동(Action)으로 다시 써주는 역할
입력(Input): 로봇이 아닌 기기(예: 자동차)에서 수집된 영상과 부정확한 GPS 신호를 입력
처리(Processing): MBRA 모델이 해당 환경에서 “만약 우리 로봇이라면 어떻게 움직였을까?”를 시뮬레이션
제약 조건 적용: 이때 로봇의 물리적 한계(최대 속도 0.5m/s, 회전 속도 제한 등)와 운동학적 모델을 강제로 적용
출력(Output): 로봇의 제어 주기(3Hz)에 맞춘 정교한 합성 액션(Synthetic actions) 라벨이 포함된 데이터셋이 나온다.
MBRA를 통해 얻은 데이터는 가짜(Synthetic) 데이터라는 점을 잊지 말 것.
품질의 한계: 아무리 MBRA가 훌륭해도 실제 로봇이 그 길을 가며 겪는 마찰력, 무게 중심의 변화까지는 완벽히 담아낼 수 없다. 그래서 논문에서도 이 데이터들을 합성 라벨이라고 부르며, 실제 데이터보다 노이즈가 많을 수 있음을 인정하고 있다.
성능의 비결: 하지만 이 가짜 데이터 덕분에 로봇은 한 번도 가보지 못한 도로(BDD-V 데이터)를 미리 눈으로 익힐 수 있었다. 이것이 OmniVLA가 보지 못한 환경(OOD)에서도 당황하지 않고 길을 찾는 비결.
BDD-V 데이터셋은 차량 대시보드에 장착된 스마트폰으로 캡처한 관측치와, 원본 논문에서 행동(actions)으로 사용된 GPS 신호의 쌍으로 구성. 다른 데이터셋과 비교하여 BDD-V는 규모가 더 크고 더 다양한 환경을 다룬다.
E. Objective design
\[\min_\theta J := J_{il} + m_{obj} J_{obj} + J_{sm}\] LeLaN[13]의 방식을 따라, 메인 목적 함수인 \(J_{il}\) 외에 추가적인 목적 함수인 \(J_{obj}\) 와 \(J_{sm}\) 을 도입하여 OmniVLA 정책 \(\pi_{\theta}\) 가 전체 손실 함수 \(J\) 를 최소화하도록 훈련
모방 학습 손실(\(J_{il}\)): 기준이 되는 N단계 액션 시퀀스와 모델이 예측한 액션 사이의 차이를 최소화
객체 도달 손실(\(J_{obj}\)): 언어 조건부 내비게이션에서 정책이 목표 객체의 포즈 \(p_{obj}\) 를 향해 이동하는 액션을 생성하도록 유도하기 위해 \((p_{obj}-\hat{a}_N)^2\) 으로 설계됨. N번째 액션인 \(\hat{a}_N\) 이 목표 객체 포즈 \(p_{obj}\) 에 가까워지도록 패널티를 부여. \(J_{obj}\) 는 오직 LeLaN 데이터셋에서 언어 그라운딩(language grounding)을 학습하기 위해서만 사용되므로, LeLaN 데이터셋인 경우 \(m_{obj}=1\) 로 설정하고 그 외에는 \(m_{obj}=0\) 으로 설정하여 마스킹 처리
액션 매끄러움 손실(\(J_{sm}\)): 액션 간의 변화량(deltas)을 최소화하여 정규화(regularization)를 수행하는 함수.
\[J_{sm}=\frac{1}{N-1}\sum^{N-1}_{i=1}(\hat{a}_{i+1}-\hat{a}_i)^2\]
- 가중치 조절(\(m_{obj}\)). 모든 데이터에 똑같은 규칙을 적용하지 않았다. 언어 데이터(LeLaN)가 들어올 때만 “목적지에 정확히 도착해!” 라는 압박(\(J_{obj}\)) 를 가하고, 일반 주행 데이터에서는 “그냥 자연스럽게 움직여” 라고 가르친 것. 이 영리한 마스킹 덕분에 모델이 여러 성격의 데이터셋 사이에서 혼란을 겪지 않고 각자의 장점만 흡수할 수 있었다.
- 로봇이 뚝뚝 끊기거나 갑자기 방향을 틀면 하드웨어에 무리가 가고 사고 위험도 커진다. \(J_{sm}\) 은 이전 액션과 다음 액션이 너무 다르지 않게 강제함으로써, 마치 숙련된 운전자가 운전하듯 매끄러운 움직임을 만들어내는 ‘브레이크’ 역할을 한다.
- OmniVLA가 단순히 ‘많이’ 배워서 똑똑한 게 아니라, 이런 세밀한 손실 함수 설계를 통해 어디로 가야 하는지(\(J_{il},J_{obj}\))와 어떻게 움직여야 하는지(\(J_{sm}\))를 동시에 균형있게 배웠다는 점을 기억
(※ 주의사항) - LoRA의 의미: 70억 개의 파라미터를 다 건드리는 것이 아니라 극히 일부만 학습시켰다는 것은, 이 모델의 근본적인 ’지능’은 이미 OpenVLA가 가지고 있던 것에 전적으로 의존하고 있다는 뜻. 베이스 모델이 얼마나 똑똑한지가 성패를 결정
데이터 편향: LeLaN 데이터셋의 비중이 4로 가장 높다. 이는 모델이 언어 지시와 객체 도달 행동에 다소 편향되어 학습되었을 가능성을 시사. 예로 만약 내가 GPS(2D pose) 성능만 중요하다면 샘플링 비율이 목적에 맞는지 의심해보아야 한다.
현실적 제약: H100 8대를 쓰고도 그래디언트 누적(Gradient Accumulation)을 4단계나 거쳤다는 사실은 이 모델이 얼마나 무거운지를 보여준다. OmniVLA-edge가 더 현실적인 대안인지 냉정하게 판단.
실험 설정에서 “진짜 실력”이 드러나는 부분은 바로 OOD프롬프트 테스트와 장애물 환경(\(SR^C\))이다.
목표 도달과 지시 이행 측면 모두에서 언어 조건부 내비게이션에는 여전히 개선의 여지가 남아있다고 Conclusion에서 언급. 여전히 오작동의 위험이 있으니, 안전이 중요한 환경이라면 2D pose(GPS)를 주 신호로 쓰고, 언어를 보조 신호로 쓰는 보수적인 접근이 필요.
GNM+BDD-V의 reannotation는 물리적 한계를 강제한 것. 모델이 자동차처럼 빠르게 움직이겠다고 날뛰는 것을 막기 위해 수학적으로 속도와 운동 모델을 좁은 틀(0.5m/s)안에 가두어버림. 이는 모델이 스스로 깨달은 게 아니라, 인간이 강제로 주입한 제약 조건.
연구팀 실험 세팅
OmniVLA: 7.5B (Llama2 7B + DINOv2 + SigLIP)
OmniVLA-edge: 50M (CLIP + EfficientNet-B0)
SmolVLA (500M), MiniVLA (1.0B), Counterfactual VLA (2.9B)
Training 환경:
NVIDIA H100 GPU 8대
OpenVLA 체크포인트 사용하여 GPU당 배치 사이즈 7, 그래디언트 누적(gradient accumulation) 4단계를 적용하여 총 224의 유효 배치 사이즈로 학습
거대 모델의 메모리 효율을 위해 LoRA를 적용하여 전체 파라미터의 약 5%만 학습 가능한 상태로 둠
평가 및 배포(Evaluation & Deployment) 환경:
실제 로봇 제어를 위한 로컬 PC에는 NVIDIA RTX 4090 GPU 탑재
로봇으로부터 전방 카메라 이미지와 포즈 신호를 수신한 뒤, 모델의 계산 결과인 속도 명령을 인터넷을 통해 로봇으로 전송하여 제어하는 방식을 취함
Dataset
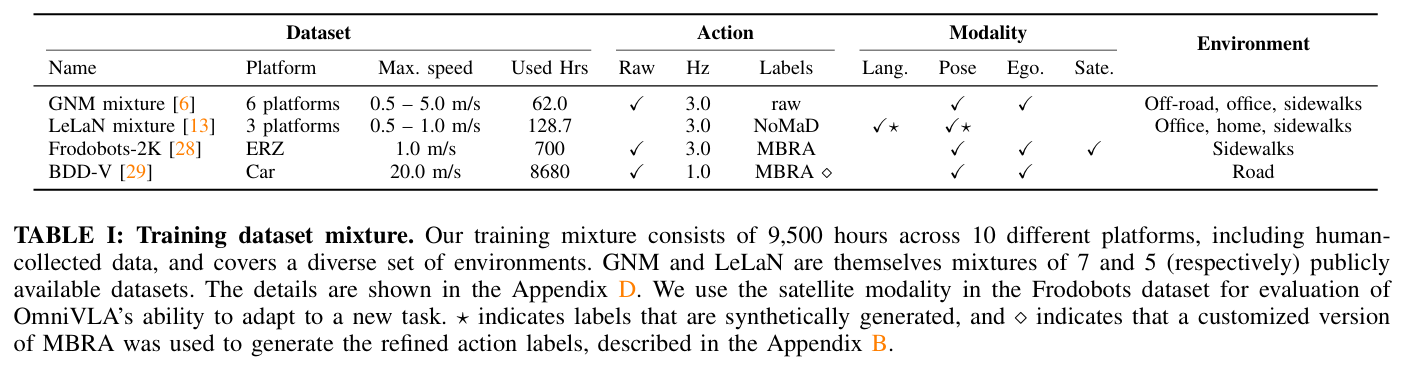
GNM mixture (7개의 로봇 데이터셋 혼합 (RECON,TartanDrive, SCAND, GoStanford2, SACSon/HuRoN, CoryHall[41], Seattle[43]))
GNM mixture 사용법: 위의 dataset 들과 학습하고 싶은 데이터(Custom Datasets section 참고)를 다운로드 후 GNM github page의
Data Processing단계를 따른다.
traj_data.pkl의 구성position: 로봇의 (x, y) 좌표 시퀀스yaw: 로봇의 헤딩(방향) 정보- 이 정보들은 이후 ’상대적 웨이포인트(Relative Waypoints)’를 계산하는 기초가 됨
데이터마다 로봇의 최고 속도와 크기가 다르기 때문에,
- 속도 기반 정규화: 로봇의 데이터 셋 별로 정의된 최고 속도(max speed) 값을 기준으로 행동 데이터를 나눈다. 이를 통해 모델은 절대적인 속도가 아닌, 해당 로봇 성능 대비 ’상대적인 이동량’을 학습
- 시간적 정규화: 로봇마다 제어 주기가 다를 수 있으므로, 일정한 시간 간격(Time horizon)에 따른 위치 변화를 예측하도록 데이터를 가공
학습을 위한 입력 데이터 구성 방식
- 시간적 문맥(Temporal Context): 현재 이미지 한 장만 보는 것이 아니라, 과거 N개(보통 5개)의 프레임을 함께 묶어 입력. 이는 로봇의 현재 운동 상태(속도, 가속도)를 모델이 파악하게 하기 위함
- 목표 이미지 쌍(Goal Pairing): 같은 경로 내에서 미래의 특정 시점 이미지를 ’목표(Goal)’로 설정하고, 현재 위치에서 해당 목표까지 가기 위한 행동을 라벨로 매칭. 이때 너무 가깝거나 너무 먼 프레임은 제외하는 필터링 과정을 거침
LeLaN mixture (SACSoN/HuRoN, GoStanford2&4[32, 46], HumanWalk, Youtube videos)
- dataset_LeLaN.zip과 dataset_LeLaN_v2.zip의 차이는?
Frodobots (MBRA 적용버전)
BDD-V (reannotation, MBRA도 fine tuning)
CAST (new language domain의 적용 가능을 보기 위한 평가 데이터)
BDD-V Dataset만 자동차 데이터였기에 로봇의 언어로 번역하는 과정(MBRA)이 필수적이었음.
custom dataset 구성법 https://github.com/robodhruv/visualnav-transformer/tree/main#custom-datasets
https://huggingface.co/NHirose/omnivla-edge/tree/main https://huggingface.co/NHirose/omnivla-original https://huggingface.co/datasets/NHirose/BDD_OmniVLA/tree/main
Related works
VLN Vision-Language Navigation. https://www.notion.so/ksko/Vision-and-language-navigation-today-and-tomorrow-A-survey-in-the-era-of-foundation-models-3103f8ca3c2280588ebecb7f743d8b95
VLM
Related paper
각 논문에서 사용된 로봇 플랫폼(실제 환경에서 테스트)
ViNT (Visual Navigation Transformer)
학습데이터
TurtleBot2
Clearpath Jackal UGV
Warthog
Boston Dynamics Spot
Yamaha Viking ATV
RC Car / 일반 승용차
성능 평가
LoCoBot
Unitree Go1: 학습 데이터에 없던 사족보행 로봇
Vizbot: 바퀴형 로봇의 일반화 테스트
Drone: 고도 제어는 X. 평면상의 내비게이션 테스트
NoMaD (Goal Masked Diffusion Policies)
핵심 에지 연산 장치
NVIDIA Jetson Orin
온보드 카메라 시스템: 별도의 외부 센서 없이 로봇에 장착된 표준 RGB 카메라만으로 데이터를 처리하며 구동
성능 평가
- LoCoBot
OmniVLA
배포 및 테스트 플랫폼
FrodoBots ERZ (EarthRover Zero)
VizBot
Unitree Go1
파라미터 수 비교
OmniVLA: 7.5B
OmniVLA-edge: 50M
ViNT: 31M
NoMaD: 19M
- VLN
https://eval.ai/web/challenges/challenge-page/719/overview#:~:text=The%20VLN%2DCE%20dataset%20ports%20the%20Room%2Dto%2DRoom%20(R2R),code%20and%20the%20dataset%20are%20available%20here.
https://github.com/google-research-datasets/RxR
- R2R-CE, RxR-CE
https://aihabitat.org/
https://cuffyluv.tistory.com/268
https://huggingface.co/datasets/frodobots/FrodoBots-2K