VL-Nav: A Neuro-Symbolic Approach for Reasoning-based Vision-Language Navigation

Du, Yi, et al. “Vl-nav: real-time vision-language navigation with spatial reasoning.” arXiv preprint arXiv:2502.00931 (2025). arXiv (2026. 03), citation 8 (26.03.19 기준)
- End-to-End 가 아닌 모듈형 구조로 Navigation Task 수행하는 논문.
- Edge(NVIDIA Jetson Orin NX)에서 YOLO-World, FastSAM 사용, 작업 분해나 재계획이 필요할 때만 RTX 4090 Laptop의 Qwen3-VL-8B model 호출하여 이용 (비동기적)
- VLM(Qwen3-VL), Scoring Policy, YOLO-World, FastSAM, 3D Scene Graph, SLAM, FAR Planner 등 너무 많은 요소가 들어감
University at Buffalo 동일 연구팀 관련 연구
Du, Qiwei, et al. “Fast task planning with neuro-symbolic relaxation.” IEEE Robotics and Automation Letters (2026). IEEE Robotics and Automation Letters 2026, citation 4 (26.03.19 기준)
Liu, Zuntao, et al. “Vision-Language Memory for Spatial Reasoning.” arXiv preprint arXiv:2511.20644 (2025). arXiv (2025. 11), citation 0 (26.03.19 기준)
Wang, Chen, et al. “PyPose: A library for robot learning with physics-based optimization.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023. CVPR 2023 (2025. 11), citation 54 (26.03.19 기준) document, github
…
문제 정의: 기존의 로봇 내비게이션은 “소파로 가라”와 같은 명시적 명령에는 강하지만, 오늘 비가 올 것 같으니 적절한 옷을 찾아라 같은 추론이 필요한 명령에는 한계를 보임.
기존 방법 End-to-End 학습 모델의 경우 데이터 의존도가 너무 높고 실세계 적용이 어려움
기존 방법 모듈형 아키텍처는 탐색 효율이 떨어져 목적 없이 방황하는 경우가 많음. 로봇은 “rain”라는 단어에서 “rain jacket”이나 “umbrella”를 떠올리고, 이를 미지의 환경에서 효율적으로 찾아내야 한다.
논문 제안 아이디어: Neuro-symbolic(NeSy) vision-language navigation system - 신경망 추론과 상징적(Symbolic) 지도를 결합
NeSy 작업 계획기(Task Planner): Symbolic 3D scene graph와 image memory system을 활용하여, 작업 분해 및 replanning을 위한 VLM의 신경망 추론 능력을 강화
NeSy 탐색 시스템(Exploration System): 신경망 시맨틱 큐(Cues)와 symbolic heuristic function을 결합하여, 탐색 중 불필요한 반복 이동을 최소화하면서 task 관련 정보를 효율적으로 수집
Methodology
- 로봇이 어떻게 인간의 말을 듣고(VLM), 기억하며(Symbolic Memory), 효율적으로 움직이는지(Exploration)에 대한 기술적 설계도
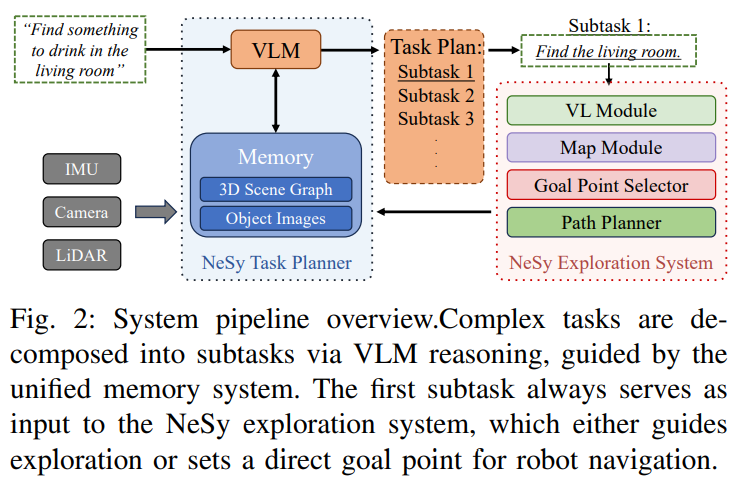
아키텍처 구성
NeSy Task Planner: 3D Scene Graph와 Object Image 메모리로 구성된 통합 symbolic memory를 통해 VLM의 신경망 추론을 안내하며(
?), 복잡하고 추상적인 지를 ‘탐색(exploration)’ 및 ’이동(go to)’이라는 atomic subtasks으로 논리적 분해NeSy Exploration System: 경량 open-vocabulary detection models (OVDMs)의 neural semantic cues와 symbolic heuristic function을 결합하여, pure VLM-in-the-loop 방식의 계산 병목 현상 없이 unknown environments를 효율적으로 탐색
NeSy Task Planner
- 통합 메모리 시스템 (Unified Memory System) - 3D Scene Graph와 객체 중심 이미지 메모리로 구성됨.
- 3D Scene Graph: object nodes와 room nodes 두 가지 유형으로 구성. 형태학적 연산(morphological operations)을 기반으로 한 room segmentation algorithm을 사용하며 LLM을 통해 각 방의 labels를 추론(예: 거실, 주방) 객체와 방 사이의 연결(Edge)은 객체의 중심점이 방의 마스크 내에 포함되는 지 여부로 결정
- Object nodes: Open-vocabulary detector에 의해 생성되며,
- 객체 중심점(object centroid)
- 탐지 신뢰도(the highest-confidence detection score)
- 탐지 당시의 로봇 포즈(robot’s pose at the viewpoint of this detection)
?여기서 pose는 위치인지 체크 - 해당 위치에서의 최적 RGB 이미지(corresponding best-viewpoint RGB image) 를 저장. 이는 공간적·관계적(spatial·relational) Grounding을 위한 토대가 된다.
- 작업 분해 및 재계획 (Task Decomposition and Replanning)
- Qwen3-VL을 VLM 백본으로 사용, 복잡한 지시를 하위 작업으로 분해. 시스템은 하위 작업이 완료될 때마다 재계획(Replanning)을 수행하며 타겟 획득을 위해 다음과 같은 ‘Coarse-to-fine(거칠게 찾고 정밀하게 검증)’ 전략 사용
- Symbolic Filtering: 3D Scene Graph를 통해 신뢰도(confidence)가 높은 상위 k개의 후보를 제안
- Neural Verification: VLM이 저장된 최적 이미지와 주변 노드 정보를 분석하여, 어떤 객체가 추상적 지시(abstract instruction)와 시맨틱하게 가장 잘 일치하는지 최종 판단
- Qwen3-VL을 VLM 백본으로 사용, 복잡한 지시를 하위 작업으로 분해. 시스템은 하위 작업이 완료될 때마다 재계획(Replanning)을 수행하며 타겟 획득을 위해 다음과 같은 ‘Coarse-to-fine(거칠게 찾고 정밀하게 검증)’ 전략 사용
- 통합 메모리 시스템 (Unified Memory System) - 3D Scene Graph와 객체 중심 이미지 메모리로 구성됨.
NeSy Exploration System
- 이 모듈은 planner의 지시를 받아 neural semantic cues와 symbolic geometric heuristics을 융합하여 실행
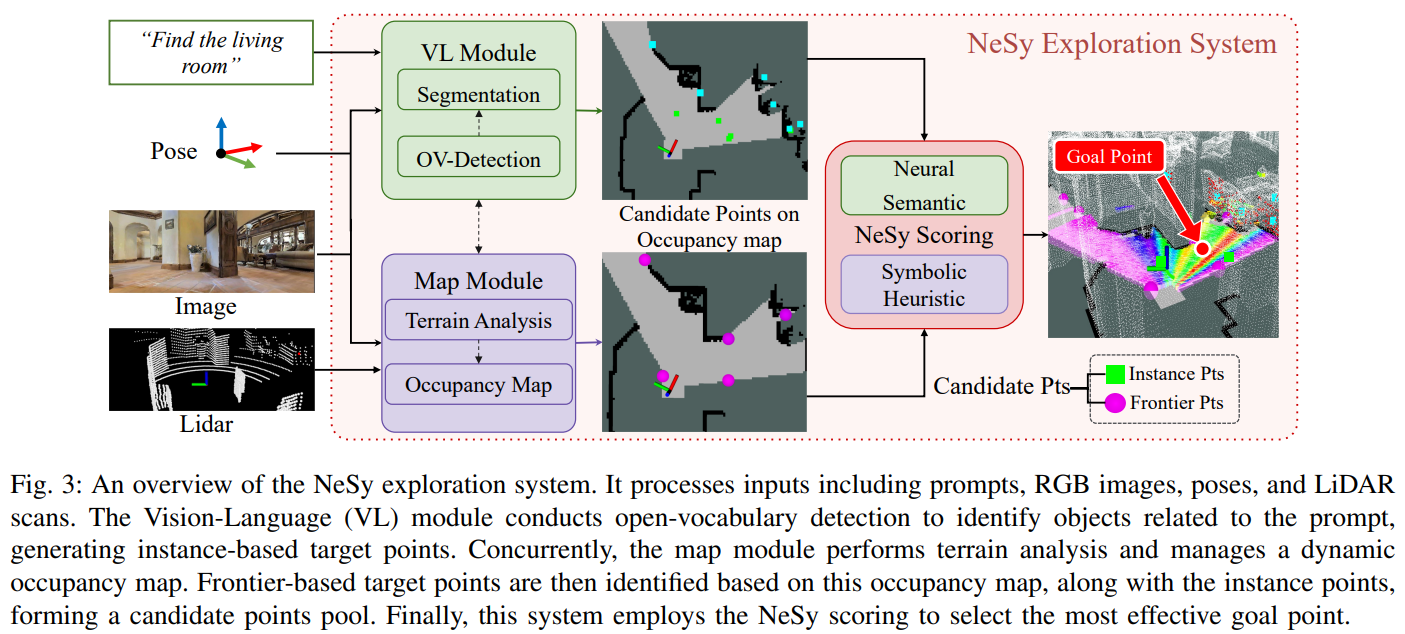
로봇은 어디로 갈지 결정하기 위해 두 종류의 후보 지점을 생성한다.
프런티어 기반 타겟 포인트 (Frontier-based Target Points)
- 로봇이 가본 곳(Free)과 안 가본 곳(Unknown)의 경계를 ’Frontier’라고 함. 지도를 넓히기 위한 후보
인스턴스 기반 타겟 포인트 (Instance-Based Target Points, IBTP)
- vision-language detector (VL Module)가 타겟일 가능성이 높은 위치의 좌표와 신뢰도(\(q_x\), \(q_y\), confidence)를 보고. 신뢰도가 임계값(\(\tau_{det}\))을 초과하면 이를 유효한 목표 후보로 간주.
- VL Module은 YOLO-World, FastSAM 사용
NeSy Scoring Policy
\[S_{\text{NeSy}}(\mathbf{g}) = w_{\text{dist}} S_{\text{dist}}(\mathbf{g}) + w_{\text{VL}} S_{\text{VL}}(\mathbf{g}) · S_{\text{unknown}}(\mathbf{g})\]
\(S_{\text{dist}}\): 에너지를 아끼기 위해 더 가까운 목표에 가중치 \[S_\text{dist}(\mathbf{g})=\frac{1}{1+d(\mathbf{x_r,\mathbf{g}})}\]
- 수식의 형태가 1/(1+d)로 거리가 0일 때 점수는 1이 되고, 멀어질수록 0에 수렴. (분모가 0이 되는 것을 방지하기 위해 분모에 1을 더함)
\(S_{\text{VL}}\): 시각 지능 모델이 예측한 타겟 존재 확률을 반영
- 타겟 존재 확률을 Gaussian Mixture Model(GMM) 분포로 변환하여 시야 내 가치맵 생성
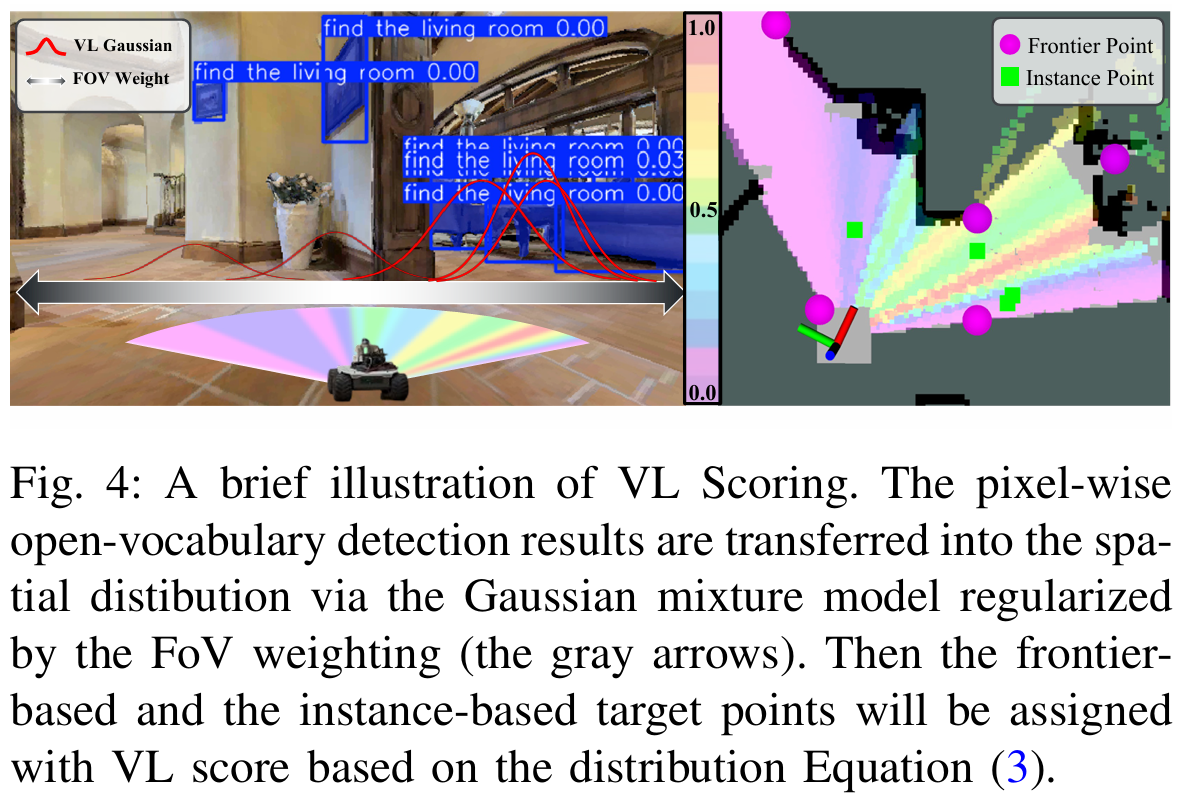
\[S_{\text{VL}}(\mathbf{g})=\sum^{K}_{k=1}\alpha_k\ \text{exp}(-\frac{1}{2}(\frac{\Delta \theta - \mu_k}{\sigma_k})^2) · C(\Delta \theta)\quad(3)\]\[C(\Delta \theta)=\text{cos}^2(\frac{\Delta \theta}{\theta_{\text{fov}/2}}·\frac{\pi}{2})\quad(4)\]
\(\Delta \theta\) : 로봇과 목표 사이의 각도. 로봇이 현재 바라보는 정면 방향과 가상의 목표 지점 (\(\mathbf{g}\)) 사이의 각도 차이
\(\mu_k\) : 물체가 발견된 진짜 방향
\(\sigma_k\) : 탐지의 불확실성. 물체가 발견된 방향이 얼마나 정확한지, 혹은 퍼져있는지를 나타냄. 논문에선 0.1이라는 고정 값 사용
\(C(\Delta\theta)\) : 정면에 대한 가산점. 정중앙 시야에서 본 것을 더 신뢰, 정면에서 멀어질수록 점수를 깎는 역할
?fov/2: 전체 시야각의 절반을 의미. field of view (FoV). 수식에서는 보통 시야의 경계선으로 사용. 로봇의 정 중앙(\(0\degree\))으로부터 시야의 왼쪽, 오른쪽 끝까지의 각도 거리.-여기서 \(\frac{\Delta\theta}{\theta_{\text{fov/2}}}\)의 최소값은 -1, 최대값은 1. (코사인에 들어가면 0)\(K\): 화면 안에서 발견된 타겟 후보 구역의 총 개수
수식 작동 원리
- 가우시안 분포(exp 부분): \(\Delta\theta\)(내가 가려는 방향)가 \(\mu_k\)(물체가 있는 방향)와 일치할 때 가장 높은 점수. 즉, 물체가 발견된 방향으로 로봇의 몸을 틀수록 점수가 올라가는 종 모양의 확률
- 타겟 존재 확률을 Gaussian Mixture Model(GMM) 분포로 변환하여 시야 내 가치맵 생성
\(S_{\text{unknown}}\): 해당 지점으로 갔을 때 얻을 수 있는 정보량(호기심) 측정 \[S_\text{unknown}(\mathbf{g}) = 1-\text{exp} (-k \frac{\#(\text{unknown cells})}{\#(\text{total visited cells})})\]
\(S_\text{VL} \times S_{\text{unknown}}\) 구조. 어떤 지점이 타겟일 확률(\(S_{\text{VL}}\))이 아무리 높아도, 이미 충분히 가본 곳(\(S_\text{unknown}\approx 0\)) 이라면 최종 점수는 낮아진다. 이미 확인한 곳보다는 아직 안 가본 있을법한 새로운 곳으로 가라는 지침
Goal Selection & Path Planning
- minimum distance threshold \(\delta_{\text{reached}}\) 를 초과하는 모든 인스턴스 기반 목표 지점(instance-based target points)을 순회. 유효한 인스턴스 목표가 존재하는 경우 검증을 유도하기 위해 \(S_{\text{VL}}\) 점수가 가장 높은 지점을 즉시 선택. 유효한 인스턴스 목표가 없거나 모두 너무 가까운 경우 시스템은 프런티어 기반 목표 지점(frontier-based target points)으로 대체. 정보 획득을 극대화하기 위해 결합된 \(S_{\text{NeSy}}\) 점수가 가장 높은 프런티어 선택.
- 목표가 선택되면, 실시간 장애물을 동적으로 회피하면서 로봇을 목표로 안내하는 충돌 없는 경로를 생성하기 위해 FAR Planner [37]을 채택.
Experiments
실험 섹션은 시뮬레이션과 실세계 로봇 플랫폼을 모두 활용하여 시스템의 추론 능력, 탐색 효율성, 일반화 성능을 검증하는 데 집중
시뮬레이션 실험: DARPA TIAMAT Challenge (Phase 1)
?DARPA TIAMAT program[1] : TIAMAT(Transfer from Imprecise and Abstract Models to Autonomous). 기존의 High-fidelity 시뮬레이션 의존 방식에서 벗어나 Low-fidelity 시뮬레이션과 추상적 모델을 활용해 자율주행 기술을 실제 환경에 신속하게 적용하는 것을 목표로 함- 핵심 가설: 다양한 Low-fidelity 시뮬레이션과 공유된 의미 체계(Shared semantics)를 결합한 학습이 High-fidelity 시뮬레이션 하나에만 의존하는 것보다 더 빠르고 강력한 Sim-to-Real 전이를 가능하게 함
?fidelity?: 현실과 얼마나 똑같은가를 나타냄. Visual Fidelity, Physical Fidelity, Sensor Fidelity… High Fidelity면 Sim-to-Real gap이 작다는 뜻으로 이해하면 됨 .. ..Phase 1의 핵심: 추상적 계획 및 의미론적 이해(APSU) 챌린지
- 목적: 로봇이 이전에 보지 못한 복잡한 환경 내에서 의미론적으로 풍부한 정보를 이해하고 행동할 수 있는지 평가
- 환경: 수행 기관들은 MiniGrid, Mujoco, Habitat, IsaacLab과 같은 기본 시뮬레이터를 사용하여 시스템을 개발
- 평가 지표: 의미적 유사성 및 정확도, 의미적 위치 측정, 시간 효율성
- Phase 1의 평가는 하드웨어가 아닌 시뮬레이션 환경 내에서만 진행
- Phase 1은 2026년 2월에 종료, 이후 실제 하드웨어 기반 Phase 2 전환.
비교 대상: VLFM[12], SG-Nav[14], ApexNav[15], VL-Nav w/o IBTP (ablation), VL-Nav w/o Curiosity (ablation).
실험 환경 및 설정
- 실내 시뮬레이션 (Habitat-Sim): The Apartment 1, Apartment 2
- 실외 시뮬레이션 (NVIDIA Isaac Sim): The Camping Site(430m x 270m), Factory(420m x 350m)
태스크 설정
- 8 abstract navigation tasks
- DARPA TIAMAT Challenge의 가이드라인을 따른 것으로, 로봇이 명시적인 물체 이름(예: “우산”)을 듣는 대신 상황적 맥락을 통해 스스로 목적지를 결정해야 하는 미션들. (우천 상황, 의료 응급 상황(“부상자가 발생했다. 도움이 될 물건을 찾아라” → [추론] 구급 상자를 찾아야 함), 정전 상황, 화재 위험 상황 등의 8가지 상황들)
- 8 abstract navigation tasks
로봇, 센서 셋업
- 이해가능한 5개의 RGB-D camera를 장착한 Boston Dynamics Spot robot
Real World 실험: Boston Dynamics의 Spot과 Unitree B2 로봇을 사용
주요 평가 지표 (Metrics)
- 성공률 (Success Rate, SR): 로봇이 타겟 객체 근처(\(\leq 1\text{m}\))에 도달하여 정지했는지 여부 측정
- 성공 경로 길이 가중치 (SPL): 경로의 효율성을 측정. 최단 경로에 가까울수록 높은 점수를 받는다.
Challenge
[1] Noorani, Erfaun, et al. “From abstraction to reality: DARPA’s vision for robust sim‐to‐real autonomy.” AI Magazine 46.2 (2025): e70015. https://www.darpa.mil/research/programs/transfer-from-imprecise
End-to-End VLA models
[9] J. Zhang, K. Wang, S. Wang, M. Li, H. Liu, S. Wei, Z. Wang, Z. Zhang, and H. Wang, “Uni-navid: A video-based vision-languageaction model for unifying embodied navigation tasks,” arXiv preprint arXiv:2412.06224, 2024.
[10] A.-C. Cheng, Y. Ji, Z. Yang, Z. Gongye, X. Zou, J. Kautz, E. Bıyık, H. Yin, S. Liu, and X. Wang, “Navila: Legged robot vision-languageaction model for navigation,” arXiv preprint arXiv:2412.04453, 2024.
[11] J. Zhang, A. Li, Y. Qi, M. Li, J. Liu, S. Wang, H. Liu, G. Zhou, Y. Wu, X. Li et al., “Embodied navigation foundation model,” arXiv preprint arXiv:2509.12129, 2025
Path Planner? [37] F. Yang, C. Cao, H. Zhu, J. Oh, and J. Zhang, “Far planner: Fast, attemptable route planner using dynamic visibility update,” in 2022 ieee/rsj international conference on intelligent robots and systems (iros). IEEE, 2022, pp. 9–16.
? “2층으로 가서 검은 상자 위에 있는 생수를 찾아 흰 옷을 입은 남자에게 전달하십시오.” 이런 명령이 주어졌을 때, 로봇이 알고 있는 정보는? 지도가 주어지고 계단, 생수, 흰 옷을 입은 남자의 위치를 이미 알고있는 상태인가? - X. 로봇은 지도를 전혀 모르는 상태(Completely Unseen/Unknown Environment)에서 시작. 이 시스템의 핵심 도전 과제는 완전한 미지의 환경에서 인간의 지시를 수행하는 것. - 실시간 맵 생성(LiDAR, 카메라)를 통해 지도를 실시간 구축 - 지도의 빈 공간(미탐색 구역)을 ’프런티어’로 정의하고, 어디로 가야 타겟을 찾을 확률이 높을지 계산하며 움직인다.